まだ重たいCMSをお使いですか?
毎秒1000リクエスト を捌く超高速CMS「adiary」
毎秒1000リクエスト を捌く超高速CMS「adiary」
2009/08/09(日)PostgreSQLトランザクションとDBD::Pgの謎の挙動

PostgreSQLのトランザクションの仕様
CREATE TABLE test(x INT UNIQUE); INSERT INTO test (x) VALUES (1); INSERT INTO test (x) VALUES (2);
としておきます。
ここで、
=> BEGIN; => INSERT INTO test (x) VALUES (3); INSERT 0 1 => INSERT INTO test (x) VALUES (1); ERROR: duplicate key value violates unique constraint "test_x_key"
とするとエラーになります。PostgreSQLはトランザクション中にエラーが起こると、以後何をしてもエラーになり受け付けなくなります。ためしに続けて色々発行してみても、
=> INSERT INTO test (x) VALUES (10); ERROR: current transaction is aborted, commands ignored until end of transaction block => INSERT INTO test (x) VALUES (20); ERROR: current transaction is aborted, commands ignored until end of transaction block
こんな感じです。COMMITすると
=> COMMIT; ROLLBACK
このようにROLLBACKされます。これがPostgreSQLの仕様です。
DBD::Pgの謎
- 確認環境
- PostgreSQL 8.3.7
- DBD::Pg Ver1.49
DBD::Pgの場合
01: $dbh->begin_work;
02: $dbh->do('INSERT INTO test (x) VALUES (10)');
03: $dbh->do('INSERT INTO test (x) VALUES (1);');
04: $dbh->do('INSERT INTO test (x) VALUES (20);');
05: $dbh->commit;
とすると、3行目でエラーが起こり、4行目の実行でも"ERROR: current transaction is aborted, commands ignored until end of transaction block"といわれます。
これを、DBIのprepareを使用して
01: $dbh->begin_work;
02: $dbh->prepare('INSERT INTO test (x) VALUES (?)')->execute(10);
03: $dbh->prepare('INSERT INTO test (x) VALUES (?)')->execute(1);
04: $dbh->prepare('INSERT INTO test (x) VALUES (?)')->execute(20);
05: $dbh->commit;
とすると、3行目でエラーが起っても、4行目の実行が反映されてしまいます。謎の挙動です。
謎の解析
このようにソースを改変してログを取ってみました。
open(my $fh, ">pg_log.txt");
$dbh->pg_server_trace($fh);
$dbh->begin_work;
$dbh->prepare('INSERT INTO test (x) VALUES (?)')->execute(10);
$dbh->prepare('INSERT INTO test (x) VALUES (?)')->execute(1);
$dbh->prepare('INSERT INTO test (x) VALUES (?)')->execute(20);
$dbh->pg_server_untrace();
close($fh);
このときサーバに対して次のようなコマンドが発行されていました。
=> BEGIN; => INSERT INTO test (x) VALUES (10); => INSERT INTO test (x) VALUES (1); エラー : duplicate key value violates unique constraint "test_x_key" => ROLLBACK; => BEGIN; => INSERT INTO test (x) VALUES (20); => COMMIT;
どうりで最後のCOMMITが成功するはずです。取得した生ログも置いておきます。
これを、
01: $dbh->begin_work;
02: $dbh->prepare('INSERT INTO test (x) VALUES (10)')->execute();
03: $dbh->prepare('INSERT INTO test (x) VALUES ( 1)')->execute();
04: $dbh->prepare('INSERT INTO test (x) VALUES (20)')->execute();
05: $dbh->commit;
とすると再現しません。prepare中にUNIQUE制約をチェックして、勝手にrollbackしているようですが、原因がPostgreSQL側なのかDBD::Pg側なのかは絞り込めませんでした。
追記
DBD::Pgの実装仕様みたいです。トラックバックを参考にしてください(iakioさんに感謝)。
DBD::Pgを直すとすれば、プレースホルダが破棄されてもトランザクションが終了するまでDEALLOCATEするのを待つ、くらいでしょうが。
明示的なトランザクション内でのエラーとDEALLOCATE
ROLLBACKしていいから、DEALLOCATE後に空のトランザクションを begin して、失敗させてくれればそれで十分な予感。
メモ
- どちらの場合も $dbh->commit(); の戻り値は "1" で成功している。
2007/12/01(土)IIS + ActivePerl で ImageMagick のインストール

ActivePerl に ImageMagick をインストールする
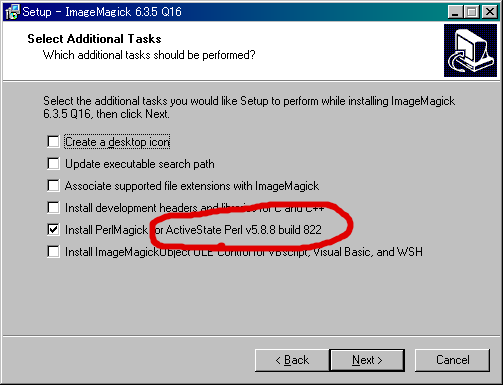
- ImageMagick公式サイトからWindowsバイナリ(-windows-dll.exe)をダウンロードしインストーラーを上の画面まで進める。
- インストーラーの画面から、対応するActivePerlのVersionとビルドナンバーを確認したら(この場合 Ver5.8.8 build 822)インストールせずに一度インストーラーを閉じる。
- 今確認したバージョンの ActivePerl インストールする
- ImageMagickを上記画面で「Update executable search path」「install PerlMagick」の2つにチェックを入れてインストールする。
これで ImageMagick がインストールされているはずです。コマンドラインで次のように入力すると手動で確認できます(エラーがでなければ正常です)。
c:\>perl -e "use Image::Magick"
IIS で ImageMagick を使う場合
IISで ImageMagick を使う CGI などを起動する場合は、更にWindowsを再起動します。
Image::Magick関連のDLLをロードさせるためにパス情報が設定されるのですが(環境変数PATH)、IISに新しいPATHを認識させるためには再起動しなければなりません。
2007/04/26(木)perl の Encode で find_encode は使えるのか?

perl tips - Encodeを速く使う方法によると、find_encoding を使うと、Encode による文字変換が早くなるらしいということで実験してみました。
実験条件
- use utf8 しない(use utf8 はトラブルが多すぎてやってられないので)。
- 変換前も変換後も utf8 フラグは立っていないこと。
- 実験用データとして、42KBのテキストファイル(EUC-JP, 日本語半分ぐらい)を用意。
ソースはこんな感じです。引数に処理したい euc-jp のテキストファイル名を与えます。
use strict;
use Benchmark;
use Encode;
use Encode::Guess qw(euc-jp shiftjis iso-2022-jp);
my $euc = join('', <>);
my $utf = $euc;
Encode::from_to($utf, "euc-jp", "utf8");
my $euc_obj = find_encoding('euc-jp');
my $utf_obj = find_encoding('utf8');
my %test;
$test{fromto_u2e} = sub {
my $x = $utf;
Encode::from_to($x, "utf8", "euc-jp");
};
$test{fromto_e2u} = sub {
my $x = $euc;
Encode::from_to($x, "euc-jp", "utf8");
};
$test{find1_u2e} = sub {
my $x = $euc_obj->encode( $utf_obj->decode($utf) );
};
$test{find1_e2u} = sub {
my $x = $utf_obj->encode( $euc_obj->decode($euc) );
};
$test{find2_u2e} = sub {
my $x = $utf;
Encode::_utf8_on($x);
$x = $euc_obj->encode( $x );
};
$test{find2_e2u} = sub {
my $x = $euc_obj->decode($euc);
Encode::_utf8_off($x);
};
$test{encode_u2e} = sub {
my $x = $utf;
Encode::_utf8_on($x);
$x = encode('euc-jp', $x);
print $x;
};
$test{decode_e2u} = sub {
my $x = decode('euc-jp', $euc);
Encode::_utf8_off($x);
};
timethese(1000,\%test);
結果は次のとおりになりました。
| 方式 | utf8 to euc | euc to utf8 |
|---|---|---|
| from_to | 100.26/s | 336.84/s |
| find_encoding | 103.92/s | 380.20/s |
| find_encoding + _utf_on/off | 357.21/s | 397.93/s |
| encode/decode | 304.76/s | 350.68/s |
utf8からutf8(フラグ付き)への変換=utf8文字列の検証が入らないので速くなりましたが、ほかは大して変わりません。use utf8 しない環境では find_encodeを使うほどでもないなぁーという感じもします。
つまり、utf8を他の文字コードに変換する場合は、Encode::_utf8_on() + encode を使うと速い。短い文字列を多量に処理するのでなければ、ほかは大して変わらない。ということだと思います。
というわけで
早速adiaryに組み込んでみよう(笑)
2007/01/13(土)perl の import の働き

use と require と import の関係
perldoc perlmodによると、use というのは次と等価と書かれています。
use Module; use Module LIST;
はそれぞれ、
BEGIN { require Module; import Module; }
BEGIN { require Module; import Module LIST; }
と等価になります。
BEGINとは?
BEGIN というのは、perl がそのソースファイルをロード中、発見次第最初に1回だけ実行する構文であるという意味です。少しフォローしておくと、モジュールのロードは、@INCにあるパスを順番に見てロードされますが、lib/ 以下に自作モジュールがあるとき、
push(@INC, './lib'); use Module;
はエラーとなります。先に use (BEGIN内構文)が実行されて、@INCにパスを追加する前にモジュールのロードが発生するからです。
use lib './lib'; use Module;
や、
push(@INC, './lib'); require Module; import Module;
とする必要があります。END { }なんてのもありますが、脱線はこれぐらいにして本題に入りましょう。
import がない場合
モジュールをロードし perl の名前空間に展開するならば、基本的には require すれば足ります。
---test.pm--- package test; sub new { return bless({}, shift); } ---test.pl--- require test; my $obj = new test();
ちなみに require では実行する度に処理されてしまうので無駄になりますから、
use test (); BEGIN { require test; } と等価
とします。import しなくても、ロードしたライブラリを使えるわけです。ではインポートとは何なのか?
import の役割
import は外部ライブラリの関数をあたかも自分の関数のように扱う仕組みです。正確に言えば、外部ライブラリの関数を自分の名前空間内に展開する仕組みが import です。例を見てみましょう。
---test.pm--- use Exporter; #←必須です package test; our @ISA = qw(Exporter); #←必須です our @EXPORT = qw($X &sum); our @EXPORT_OK = qw($Y); our $X = 10; our $Y = 20; sub sum { return ($_[0]+$_[1]); #渡された引数2つを加えて返す処理 } print "in test.pm : X=", \$X, "\n";
呼び出し側はこんな感じです。
use test; # BEGIN {require test; import test;} と等価
our ($X, $Y);
print "X=$X ", \$X, "\n";
print "Y=$Y\n";
print sum(5,3),"\n";
として実行してみます。
in test4.pm X=SCALAR(0x93bc130)
X=20 SCALAR(0x93bc130)
Y=
30
となります。test という名前空間内の変数 $X、関数 sum が、import した側で使えるようになっています。perl 的に正確に言えば、$test::x と &test::sum の示す実体が(内部的な実体のポインタが)それぞれ $MAIN::x、&MAIN::sum にコピーされたことになります。その証拠に、リファレンスをとって実体を調べると、ともに同じ実体である SCALAR(0x93bc130) を示しています。
import される関数は、モジュール側で @EXPORT に代入されているものになります。
import の引数は何?
import は配列引数を取れることになっています。これは、モジュール側で @EXPORT および @EXPORT_OK に代入されているもののうち、どれをインポートするか指定する役割があります。
ですから、さきほどのソースで、
use test qw(&sum $Y);
と変更すると次のような結果になります。
in test4.pm X=SCALAR(0x953e1b8)
X= SCALAR(0x94fd660)
Y=10
30
$Yがインポートされている反面、$X が test.pm 内の実体とは違うものを示していることが分かります。
関連記事
2006/12/04(月)Perlと標準入出力ファイルハンドル

Perlで「use strict」で使用している場合、ファイルハンドルを動的に生成し変数に代入するには一工夫する必要がありました。
さらに、このファイルハンドルに標準入力などを代入する場合、
my $fh = 'STDOUT';
ではダメで、
my $fh = *STDOUT;
とします。少々気持ち悪い感じもしますが、STDOUTという定義済の名前に対する型グロブを与えることになります。Symbolなどのライブラリをみると分かりますが、動的ファイルハンドルの実体は、特定の名前に対する型グロブになっています。